Assuring Large Language Models
LLMs you Can Trust to Speak on your Behalf.

Assuring Large Language Models
If thought corrupts language, language can also corrupt thought.


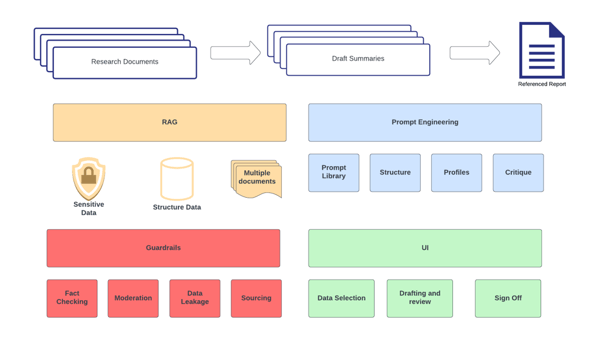
Leverage the Alignment framework to de risk and secure the outputs of generative AI.
Adjust controls depending on the use-case and context of your model deployment. Risk appetites will differ between customer facing tools and the internal tools.
Enable key internal stakeholders to grasp how AI language models interpret knowledge and form responses.
Well managed risk will promote trust, stakeholder confidence and user adoption.
Advai Guardrails come complete with end-to-end documentation that highlights the rigorous robustness assurance methods employed.
This acts as a safety net against regulatory challenges and assures that your organisation's AI operations are both safe and compliant.
With Advai's robust alignment and testing, enjoy peace of mind knowing that your LLM will function as intended in various scenarios.
As a cutting edge field, novel methods to control LLMs are discovered every week.
Our team of researchers and ML engineers keep your LLM guardrails updated.
Adversarial attack methods are released almost weekly. Keeping on top of novel attack vectors will reduce the chance of your business saying something it will regret.
Meet the competitive pressure to deploy without undue risk.
Assurance needs to come first, not last. The faster you can assure your system, the faster you can deploy.
Ensure the reliability of your Large Language Models (LLMs) with our comprehensive robustness assessments.
Win the confidence of key stakeholders using empirical methods to demonstrate that your model is fit for purpose.
Our adversarial attacks have been optimised across multiple models with different LLM architectures, therefore having relevance to a broader landscape of verification methods. We have demonstrated that this enables us to successfully conduct “one shot” attacks on multiple unrelated systems.
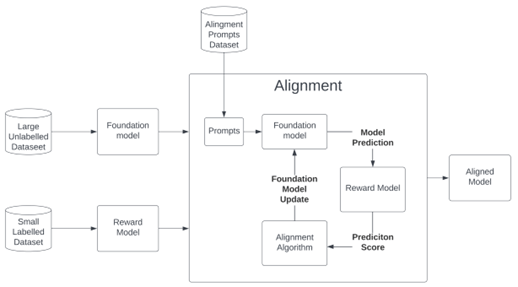
We enable businesses to fine-tune and control Large Language Models (LLMs) to align with organisational risk appetites and operational requirements.
Our approach places a heavy emphasis on ensuring the quality of reward models used in LLM fine-tuning. We counter this by using algorithmically optimised suffix attacks (see more below).
We carry out advanced self-optimising suffix attacks to discover out-of-sample attack vectors (unfamiliar strings of text input) that reveal novel methods of bypassing guardrails and manipulating LLMs to perform undesirably. This reveals vulnerabilities to address.

‘Low-hanging fruit’ integration: Address high impact & ‘best-for-LLM’ tasks, then expand and advance in complexity.
Recognise weaknesses of AI: targeted human in-the-loop.

Industry state-of-the-art approach: Plan and integrate on modular basis, expecting the tech to rapidly evolve.
Collaboration: ensure your team understands what is going on, and that analysts understand responsibilities and opportunities.


